A Digital Analysis of "Lyrical" Novels.
Summer 2018 - April 2019
My honors thesis for the University of Virginia Distinguished Majors program consisted of a digital study of “lyrical” novels in order to better define this heretofore amorphous, nebulous term. I was graciously advised by Brad Pasanek and Paul Cantor.
(Editor’s Note: You can read about the month to month work of my thesis over on the blog, and view the completed paper right here) and download my slide deck from my presentation of this thesis at 2019 Digital Humanities and Computer Science Colloquium here.
I’ll begin with the abstract.
The class of novels referred to as “lyrical” by critics and readers deserves comprehensive inspection and evaluation. Virginia Jackson creates space for me to start this analysis as she recognizes a fraught conception of “lyrical” poetry. Friedrich Nietzsche and Ralph Freedman inform my view of potential formal features that signal whether or not a novel is “lyrical.” My project takes up this task from an untraditional perspective. I implement state of the art machine learning algorithms and computational analysis to understand the formal elements that make a novel “lyrical.” Franco Moretti’s school of “distant reading” looms large in this type of analysis. This project is enabled through my creation of a database containing every word, sentence and paragraph of fifty novels – half “lyrical,” half detective fiction as a control set. I complement my digital work with traditional close readings. Through my paper, I hope to show that digital methods of scholarship are readily compatible with time tested styles of critique. I advocate for further digital scholarship in this space, but of the proper variety: balanced and transparent. Ultimately, I make the case that the most salient feature of “lyrical” novels is their reliance on anaphora
Now let’s unpack all that. In order to study lyrical fiction, I first needed a group of books. I sourced my group of novels based on publications, recommendations from professors, book jackets. critical surveys, etc. I used detective fiction as a control corpus. This aspect of my project was inspired by Franco Moretti’s corpus experiments in Canon/Archive where he contends that genre fiction is rhetorically stable and thus presents a beneficial contrast to the indefinite posture assumed by lyrical works. Ultimately, I worked with a set of 50 books.
The definition of “lyrical” I lean on throughout my project is informed most chiefly by Virginia Jackson. Jackson’s coins the term “lyricization” to denote the phenomenon of (unconsciously) classifying disparate forms of poetry as lyric and implicate most all verse as apparently without context, highly expressive and personall regardless of its form or content. In essence, the aim of my project was to provide a computational rigor to her claim.
To work with these texts, I split them into their words, sentences and paragraphs with a course of R and Python routines. (This work is all in the project repo). Then I committed these values to a SQLite database. SQLite was incredibly easy to use; my database schema ended up being nothing more than a single table (following the lead of Raf. Alvarado’s concept of the “data-lake”).
From there I created a feature set of 31 potential markers of “lyrical” novels. The data points ranged from the simple (number of commas per sentence) to the novel (I calculated a moving-average Type-Token Ratio for each novel in order to combat the skewing effect of input size on this long-standing measure of lexical richness). Some of the features were inspired by critical studies. For example, Ralph Freedman’s The Lyrical Novel stresses the importance of visual verisimiltude in “lyrical” fiction. So, I quanitified simile and metaphor with help from The Harvard Inquirier body of word modalities. And in step with the writing of Nietzsche in The Birth of Tragedy, I do my best to estimate sonic richness with measures of syllabic richness. (This particular area that could have easily comprised its own project, and one that I would love to explore more deeply.)
Here is a snapshot of these features for some of the lyrical novels.
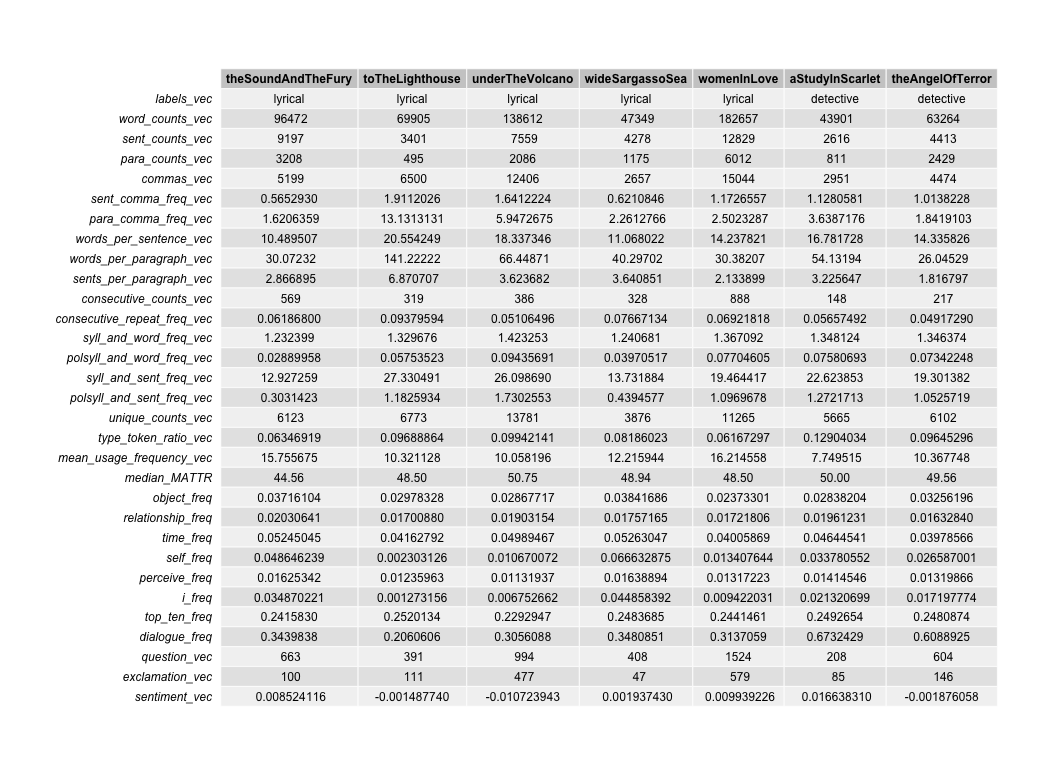
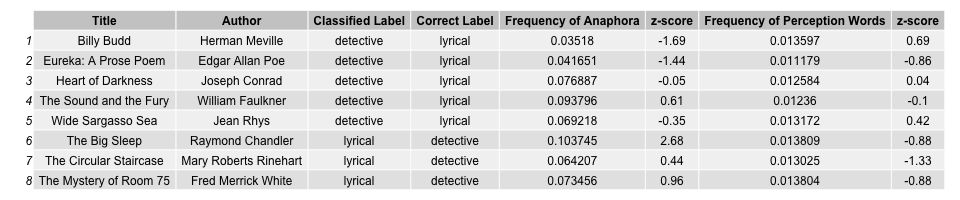
My idea was to leverage this large feature set and use a combination of supervised learning and close-reading to determine the most consequential. Regarding the former, I built a SVM using the two most extreme variables from an initial trial run. The levels “anaphora-frequency” and “perception-frequency” across my corpus were placed into this model. I used “Leave-One-Out-Cross-Validation” (LOOCV) and a cost parameter of 2.5 to the tune of 84% accuracy. Just as exciting as these results was an investigation into the different works that my classifer pinned in the wrong category.
After this process, I close read my text with my feature set in hand, looking for interesting phenomenon and whether or not my computationally generated metrics fraternized with the reality of the text itself. For example, I compare Lolita and Pale Fire and I also examine the prose of To The Lighthouse.
At one point in my project I stepped away from the computer entirely and spent the week poring over Moby Dick – and who wouldn’t? I don’t need an R subroutine to tell me that sequences such as this are, without a doubt, lyrical:
“Is it not curious, that so vast a being as the whale should see the world through so small an eye, and hear the thunder through an ear which is smaller than a hare’s? But if his eyes were broad as the lens of Herschel’s great telescope; and his ears capacious as the porches of cathedrals; would that make him any longer of sight, or sharper of hearing? Not at all.—Why then do you try to “enlarge” your mind? Subtilize it”
Of course I did spend quite a lot of time at my computer during the project; I generated some very interesting visualizations during the project like this graph of syllabic variety across an internal monologue from Quentin Compson in Faulkner’s As I Lay Dying.

Ultimately, I conclude that the most consequential marker of a lyrical novel is the presence and continued invocation of anaphora. In turn, I engender broad discussions about canonization, genre and form—and questions that which lurks deep beneath the glossy surface of the celebrated novels we cling to.
The work carried out in my project injects empiricism and rigor into the claims we make about books. I cleaned a reusable corpus of canonical texts and packaged their rhetorical units in a relational database for future study. I incorporated the ideas of critical theorists. I calculated remarkably minute yet consequential markers of syntax and style in the novel. I focused attention on the invocation of anaphora and demonstrated that this measure is indicative of lyricality in novels.
My thesis modulates between digital sleuthing and the more traditional type of literary study one would expect when approaching an English thesis. I relished leveraging these different modes of investigation towards a common goal. I think the combination generated my project’s efficacy.